Aula 40 - TensorFlow - Keras - Redes Neurais - Transformers
Fontes
Recapitulando as arquiteturas
A rede neural
feed-forward não funciona bem para dados sequenciais, como texto, porque o significado das palavras depende de sua ordem na frase.
As
redes neurais recorrentes (
RNN) foram uma solução inicial para processamento de linguagem natural, mas eram lentas e não podiam lidar com longas sequências de texto.
As
redes de memória de curto prazo (
LSTM) resolveram alguns problemas, mas ainda eram lentas e limitadas pelo processamento serial.
Os
transformadores foi a solução mais recente e mais eficiente para lidar com o processamento de sequências de texto.
Tipos de problemas que as redes neurais sequenciais resolvem
Existem diferentes tipos de modelos de redes neurais para lidar com dados sequenciais.
O modelo "
vetor para sequência" usa uma
única entrada, como uma
imagem, e produz uma sequência de dados, como uma descrição.
O modelo "
sequência para vetor" usa uma sequência como entrada, como uma revisão de produto ou uma postagem de mídia social, e gera um único valor, como uma pontuação de sentimento.
Já o modelo "
sequência para sequência" usa uma sequência como entrada, como uma frase em inglês, e gera outra sequência, como a tradução da frase em francês, ou um chatbot.
Apesar de suas diferenças, todos esses modelos aprendem a representar os dados durante o treinamento, ajustando os parâmetros das camadas ocultas da rede neural para mapear os recursos da entrada para a saída de maneira mais adequada.
Seq2Seq versus Transformer
Assim como a
arquitetura seq2seq, a
arquitetura Transformer também tem um
codificador e um
decodificador.
Na verdade, a
arquitetura Transformer é uma generalização da arquitetura
Seq2Seq.
A arquitetura
Transformer se diferencia da arquitetura
Seq2Seq por não usar
redes neurais recorrentes RNN, como
LSTMs ou
GRUs (Gated Recurrent Units).
Mecanismo de atenção
O
codificador do
Transformer processa a sequência de entrada e a transforma em uma série de vetores de contexto, um para cada palavra na sequência de entrada.
A principal inovação do
Transformer em relação à arquitetura
Seq2Seq é o uso de mecanismos de atenção
multi-cabeça, que permitem que o modelo aprenda a importância relativa das diferentes palavras na entrada e atribua mais ou menos peso a cada uma delas.
O
Transformer resolve o problema de paralelização utilizando uma
subcamada de
atenção multi-head seguida por uma
subcamada feed-forward.
A atenção acelera a velocidade com que o modelo pode traduzir de uma sequência para outra.
O
Transformer é um modelo que usa
auto-atenção para aumentar a velocidade.
Ele consiste em seis codificadores e seis decodificadores, cada um com a mesma arquitetura.
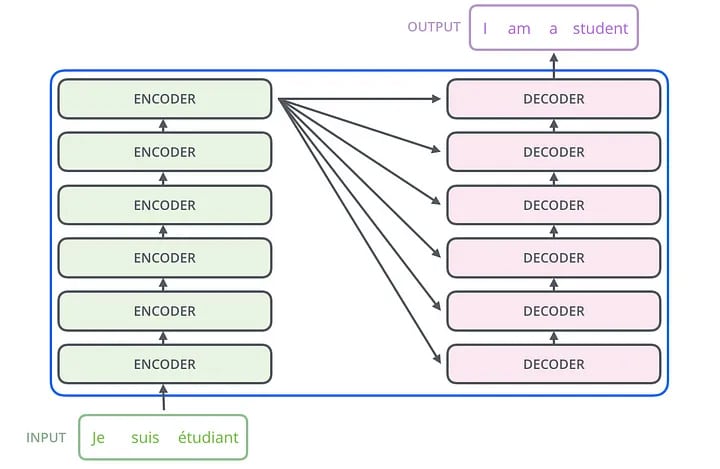
Cada codificador(
encoder) possui
duas camadas:
auto-atenção e uma
rede neural de feedforward.
Codificador
As entradas do codificador primeiro fluem através de uma camada de auto-atenção.
Ele ajuda o codificador a olhar para outras palavras na frase de entrada enquanto codifica uma palavra específica.
Decodificador
O decodificador tem essas duas camadas, mas entre elas há uma camada de atenção que ajuda o decodificador a se concentrar nas partes relevantes da frase de entrada.
Mecanismo de atenção humana
Como divulgado em um estudo publicado na revista científica
sciencedaily, o nosso cérebro está constantemente tentando prever a próxima palavra, seja durante a leitura de um livro ou ao ouvir um discurso.
Essa descoberta revela a atividade cerebral envolvida no processamento da linguagem.
Mecanismo de atenção da máquina
O mecanismo de atenção, tanto
LSTM ou
GRU, no caso das
RNNs seq2seq, como no mecanismo de atenção do
Transformer, chamado de
multi-cabeça, tenta reproduzir o mesmo que o nosso cérebro faz quando está prestando atenção, envolvido em uma conversa.
Esses mecanismos:
LSTM ou
GRU, nas
RNNs e o
multi-cabeça, são especialmente importante para entender o contexto em tarefas de processamento de linguagem natural, como tradução automática e geração de texto.
RNNs seq2seq vs.Transformer - processamento
O
Transformer é mais eficiente que o
seq2seq com
LSTM em processar sequências longas, pois o
seq2seq processa as sequências em uma única dimensão, o que limita a paralelização.
O
Transformer usa um mecanismo de atenção
multi-cabeça para dividir as sequências em várias partes, permitindo que o modelo processe simultaneamente diferentes partes das sequências de entrada e saída, tornando-o mais rápido e eficiente.
Isso é uma vantagem significativa em tarefas de processamento de linguagem natural.
RNNs seq2seq vs.Transformer - desaparecimento de gradiente
Em termos de desaparecimento de gradiente, o
Seq2Seq com
LSTM usa um algoritmo de otimização chamado de "
Backpropagation Through Time" (
BPTT), que é uma extensão do algoritmo de retropropagação padrão.
O
BPTT é uma técnica de aprendizado de máquina que permite que a rede neural aprenda a partir de sequências de dados, como sequências de palavras em um texto.
Já o Transformer usa um algoritmo de otimização chamado "
Adam Optimizer", que é um método popular de otimização estocástica de primeira ordem baseado em estimativas adaptativas de momentos de baixa ordem das grandezas de gradiente.
O Adam Optimizer é eficiente em lidar com grandes volumes de dados e é frequentemente usado para treinar modelos de redes neurais de grande escala, como o
GPT.
Limitações
Uma limitação do
BPTT é que ele pode levar a problemas de gradiente explodindo ou desaparecendo, especialmente quando a rede está sendo treinada em sequências muito longas.
Isso pode tornar o treinamento do modelo
Seq2Seq LSTM mais difícil e requerer técnicas adicionais, como o uso de redes
LSTM bidirecionais.
Já o
Transformer lida com esses problemas de forma mais eficiente através do uso de mecanismos de atenção
multi-cabeça, que permitem que a rede foque em partes relevantes da sequência de entrada de cada vez.
Além disso, o uso do algoritmo
Adam Optimizer também ajuda a melhorar a eficiência do treinamento em grandes volumes de dados.
Vanishing gradient
O
desaparecimento de gradiente é um problema em redes neurais profundas onde os gradientes propagados para camadas mais profundas se tornam muito pequenos para atualizar corretamente os pesos, enquanto a
explosão de gradiente é outro problema em que os gradientes se tornam muito grandes, o que pode causar instabilidade numérica.
Ambos os problemas são causados pela multiplicação repetida de gradientes em cada camada durante a retropropagação do erro.
Para lidar com esses problemas, técnicas como
normalização de
lotes e
truncamento de
gradientes são usadas.
Porque ocorre o problema de explosão e desaparecimento de gradiente?
Existem várias razões pelas quais o desaparecimento de gradiente pode ocorrer em redes neurais profundas.
Uma delas é a função de ativação usada nas camadas da rede.
Funções de ativação como a sigmóide ou tangente hiperbólica têm gradientes que se tornam muito pequenos à medida que os valores de entrada se tornam muito grandes ou muito pequenos, o que pode levar a gradientes insignificantes nas camadas mais profundas da rede.
Outra razão para o desaparecimento de gradiente é a inicialização inadequada dos pesos da rede.
Se os pesos forem inicializados com valores muito pequenos, os gradientes na retropropagação também serão pequenos, o que pode resultar em desaparecimento de gradiente nas camadas mais profundas.
Atualmente, existem técnicas de treinamento que ajudam a evitar o desaparecimento de gradiente em redes neurais profundas, como a normalização por camada (batch normalization) e as conexões residuais (residual connections).
Essas técnicas têm sido usadas com sucesso em arquiteturas de redes neurais profundas, como as redes convolucionais e o Transformer, que permitem treinar modelos mais profundos com maior eficiência e desempenho.
Self-Attention
O primeiro passo para calcular a
autoatenção é criar três vetores a partir de cada vetor de entrada do codificador (neste caso, a incorporação de cada palavra).
Portanto, para cada palavra, criamos um vetor de consulta (
Query), um vetor de chave (
Key) e um vetor de valor (
Value).
Esses vetores são criados multiplicando a incorporação por três matrizes que treinamos durante o processo de treinamento.
Observe que esses novos vetores têm dimensões menores do que o vetor de incorporação.
Sua dimensionalidade é 64, enquanto os vetores de entrada/saída do codificador têm dimensionalidade de 512.
Eles não precisam ser menores, isso é uma escolha de arquitetura para tornar o cálculo da atenção multihead (principalmente) constante.
Vetores
Na primeira etapa da autoatencão, criamos um "vetor de consulta", um "vetor de chave" e um "vetor de valor" para cada palavra da sentença de entrada, multiplicando a palavra pela matriz de peso
WQ.
Esses vetores são abstrações úteis para calcular e pensar sobre atenção.
Em seguida, na segunda etapa, calculamos uma "pontuação" para cada palavra da sentença de entrada em relação à palavra que estamos processando.
A pontuação é calculada multiplicando o vetor de consulta pelo vetor de chave da respectiva palavra.
Essa pontuação determina o quanto de foco devemos dar em outras partes da sentença de entrada enquanto codificamos uma palavra em uma determinada posição.
Cálculo em relação ao posicionamento
O
terceiro e o
quarto passos são dividir os scores por 8 e em seguida, passar o resultado por uma operação
softmax.
Softmax normaliza os scores para que todos sejam positivos e somem 1.
A pontuação softmax determina o quanto cada palavra será expressa naquela posição, permitindo que outras palavras relevantes sejam consideradas.
Depois, multiplicamos cada vetor de valor pela pontuação softmax e somamos os resultados ponderados para obter a saída da camada de autoatenção.
Essa saída preserva os valores das palavras importantes e diminui a importância das palavras irrelevantes.
Isso
conclui o
cálculo de
autoatenção.
O
vetor resultante pode ser enviado para a rede neural de
feed-forward.
Na implementação real, no entanto, esse cálculo é feito em forma de matriz para processamento mais rápido.
Vamos dar uma olhada nisso agora que vimos a intuição do cálculo no nível da palavra.
Exemplo
O que é um vetor em
n dimensões?
É uma forma de codificar dados com
n características.
Quando a dimensão é alta, é difícil visualizar.
Então, vamos fazer a coisa mais simples que podemos fazer.
Digamos que temos as seguintes frases:
eat apple
eat bread
drink water
drink beer
read newspaper
read book
Tabela de vetores para dimensão 2
Se gerarmos vetores de duas dimensões para essas frases (não um vetor para cada palavra, mas um vetor para cada frase), podemos criá-los como acima. (Quanto mais dimensões, melhor a codificação).
Com essa simplificação exagerada, se multiplicarmos esses vetores de frases, podemos ver que itens relacionados à comida recebem mais pontos quando multiplicados com outros itens relacionados à comida.
eat apple x eat bread = 0,8 x 0,7 + 0,1 x 0,2 = 0,58
eat apple x read book = 0,8 x 0,2 + 0,1 x 0,8 = 0,24
Isso foi para duas dimensões!
Agora, pense em quantas dimensões realmente precisamos para um problema de PNL.
Voltando ao nosso problema, nosso problema é aprender a tradução do francês para o inglês.
E nossos vetores têm 64 dimensões. Vou tentar reduzi-los para dimensão 2 ou 3.
Vetores Q, K e V
No transformer,
Q,
K e
V são vetores que usamos para obter uma codificação melhor tanto para nossas palavras de origem quanto para as de destino.
Q: Vetor (saída de camada linear) relacionado com o que codificamos (saída, pode ser a saída da camada de codificador ou da camada de decodificador)
K: Vetor (saída de camada linear) relacionado com o que usamos como entrada para a saída.
V: Vetor aprendido (saída de camada linear) como resultado de cálculos, relacionado com a entrada.
No Transformer, usamos três lugares para ter a autoatenção, então temos os vetores
Q,
K,
V.
1- Autoatenção do codificador
Q =
K =
V = nossa sentença de origem (francês)
2- Autoatenção do decodificador
Q =
K =
V = nossa sentença de destino (inglês)
3- Atenção codificador-decodificador
Q = nossa sentença de destino (inglês)
K =
V = nossa sentença de origem (francês)
Com esses vetores
Q e
K, calculamos a atenção e multiplicamos com
V.
Então, aproximadamente:
attention = Softmax( (Q * K) / Scale)
enbedding for attention layer = attention * V
Essas são apenas camadas lineares, nada muito especial.
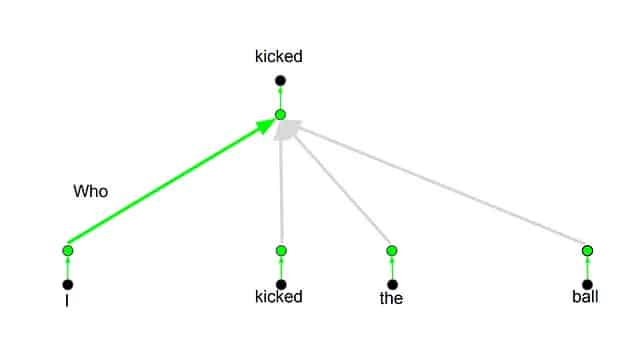
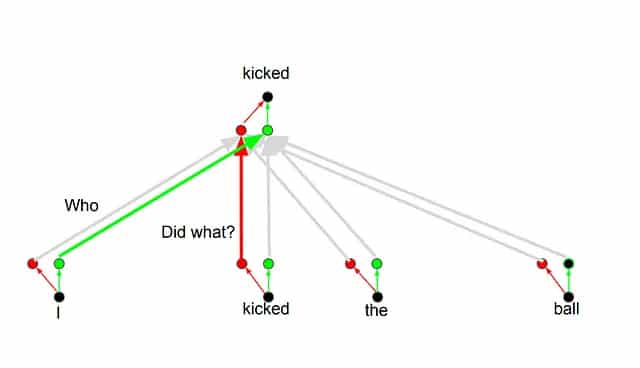
Multihead attention
Os
Transformers funcionam usando o conceito de atenção múltipla(
Multihead attention), que permite prestar atenção em diferentes dimensões durante a tradução.
Por exemplo, ao traduzir a palavra "
kicked" na frase "
I kicked the ball", é possível fazer perguntas como "
Who kicked?" ou "
Did what?". Dependendo da resposta, a tradução pode mudar.
Codificação Posicional
Posicionamento Codificado é um passo importante no Transformer e é usado para codificar a posição de cada palavra.
Isso é importante, pois a posição de cada palavra é relevante para a tradução.
Por essa aula é só, nos vemos na próxima, valeu \o/.
Meu github:
Novamente deixo meus link de afiliados:
Obrigado, até a próxima e bons estudos. ;)



