Aula 22 – Tensor Flow – Keras – Redes Neurais Convolucionais
Aula 22 – Tensor Flow – Keras – Redes Neurais Convolucionais
Voltar para página principal do blog
Todas as aulas desse curso
Aula 21 Aula 23
Meu github:
https://github.com/toticavalcanti
Documentação oficial do TensorFlow:
https://www.tensorflow.org/
Quer aprender python3 de graça e com certificado? Acesse então:
https://workover.com.br/python-codigo-fluente

Python com Tensorflow
Se gostarem do conteúdo dêem um joinha 👍 na página do Código Fluente no
Facebook
https://digitalinnovation.one/
Aproveito para deixar meus link de afiliados:
Hostinger
Digital Ocean
One.com
Toti:
https://www.youtube.com/channel/UCUEtjLuDpcOvR3mIUr-viOA
Backing track / Play-along:
https://www.youtube.com/channel/UCT3TryVMqTqYBjf5g5WAHfA
Código Fluente
https://www.youtube.com/channel/UCgn-O-88XBAwdG9gUWkkb0w
Putz!
https://www.youtube.com/channel/UCZXop2-CECwyFYmHbhnAkAw
Fiquem a vontade para me adicionar ao linkedin.
Notebook da aula
Aula 22 – Tensor Flow – Keras – Redes Neurais Convolucionais
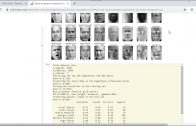
Os dígitos manuscritos são feitos de formas e descartamos as informações da forma quando achatamos os pixels.
As redes convolucionais tiram proveito das informações das formas, dos pixels vizinhos, por isso, não vamos achatar a matriz como fizemos nos exemplos anteriores.
Não vamos fazer: tf.keras.layers.Flatten(input_shape=(28, 28), name=’flatten_input’)
Porque não aproveitaríamos o que as camadas convolucionais podem oferecer em termos de reconhecimento de formas.
A vamos achatar depois de passar pelas camadas convolucionais.
Usamos apenas 4 patches na primeira camada convolucional.
Se você aceitar que esses pedaços de pesos evoluem durante o treinamento para reconhecedores de forma, você pode ver intuitivamente que isso pode não ser suficiente para o nosso problema. Dígitos escritos à mão normalmente tem mais de 4 formas elementares.
Nesse exemplo vamos aumentar um pouco os tamanhos dos patches, aumentar o número de patches em nossas camadas convolucionais de 4, 8, 12 para 6, 12, 24 e, em seguida, adicionar dropout na camada totalmente conectada.
Por que não nas camadas convolucionais?
Os neurônios reutilizam os mesmos pesos, portanto, o dropout, que funciona efetivamente ao congelar alguns pesos durante uma iteração de treinamento, não funcionaria nas camadas convolucionais.
Então partiu colab:
Notebook da aula
Por essa aula é só.
Voltar para página principal do blog
Todas as aulas desse curso
Aula 21 Aula 23
Meu github:
https://github.com/toticavalcanti
Se gostarem do conteúdo dêem um joinha 👍 na página do Código Fluente no
Facebook
Link do código fluente no Pinterest
Novamente deixo meus link de afiliados:
Hostinger
Digital Ocean
One.com
Obrigado, até a próxima e bons estudos. 😉