Aula 14 – Scikit-Learn – Reconhecimento facial – LFW – parte-02
Aula 14 – Scikit-Learn – Reconhecimento facial – LFW – parte-02
Voltar para página principal do blog
Todas as aulas desse curso
Aula 13 Aula 14
Script dessa aula:
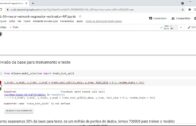
Download do script da aula
Documentação oficial do Sklearn:
https://scikit-learn.org/stable/

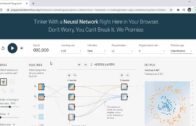
Scikit-Learn – reconhecimento facial com LFW – parte02
Se gostarem do conteúdo dêem um joinha 👍 na página do Código Fluente no
Facebook
Link do código fluente no Pinterest
Meus links de afiliados:
Hostinger
Digital Ocean
One.com
Essa aula é baseada no trabalho apresentado no:
Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments Gary B. Huang,Manu Ramesh, Tamara Berg, and Erik Learned-Miller
Para o download da base LFW é só clicar nesse link abaixo:
https://scikit-learn.org/stable/auto_examples/applications/plot_face_recognition.html
Ou da fonte original
http://vis-www.cs.umass.edu/lfw/
Como utilizar o LFW
Para o uso adequado do banco de dados, devemos proceder da seguinte forma, segundo os criadores do LFW:
- Desenvolvimento de algoritmo ou seleção de modelo.
- Use a View1 do banco de dados para treinar e testar tantos modelos e tantas configurações de parâmetros quanto se
queira. - Reter o modelo M* com melhor desempenho no conjunto de teste.
- Use a View1 do banco de dados para treinar e testar tantos modelos e tantas configurações de parâmetros quanto se
- Relatório de desempenho.
- For i = 1 to 10
- Formar um conjunto de treinamento para o experimento i combinando todos os subconjuntos da view2, exceto o subconjunto i.
- Definir os parâmetros do modelo M* usando o conjunto de treinamento, produzindo o classificador i.
- Usar o subconjunto i da View2 como o conjunto de teste.
- Registrar os resultados do classificador i sobre o conjunto de testes.
- Use os resultados de todos os 10 classificadores para calcular a precisão média estimada da classificação ˆμ e o
erro padrão da média SE. - Por fim, certifique-se de informar qual método de treinamento(restrito a imagem ou irrestrito).
- For i = 1 to 10
Precisão média estimada
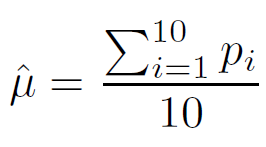
Precisão média estimada
Onde Pi é a porcentagem de classificações corretas na view2, usando o subconjunto i para teste.
É importante notar que a precisão deve ser calculada com parâmetros e limites escolhidos independentemente dos dados do teste, excluir, por exemplo, simplesmente escolhendo o ponto em uma curva Precision-Recall que nos dá maior precisão.
Erro padrão da média
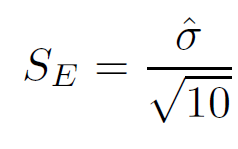
Erro padrão da média
onde σ^ é a estimativa do desvio padrão, dado por:
Estimativa do desvio padrão
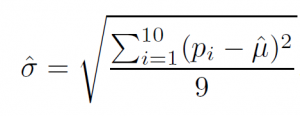
Estimativa do desvio padrão
Transitividade e o uso de IMAGE-RESTRICTED e UNRESTRICTED dos dados de treino.
Sempre que se trabalha com pares de imagens de uma mesma pessoa e outras que não são da mesma pessoa, isto é, imagens matched e imagens mismatched, como os descritos em pairsDevTrain.txt, surge a questão da criação de exemplos de treinamento auxiliar usando a transitividade da igualdade.
Por exemplo, em um conjunto de treinamento, se um par correspondente consistir em ser as imagens 10 e 12 de George_W_Bush, e outro par consiste nas imagens 42 e 50 de George_W_Bush, pode parecer razoável adicionar outros pares de imagens, como (10, 42), (10, 50), (12, 42) e (12, 50), para os dados de treinamento usando um procedimento automático.
Exemplos auxiliares podem ser adicionados aos pares incompatíveis(mismatched) usando o mesmo método.
Treinamento com Image-Restricted
A ideia por trás do paradigma restrito à imagem(Image-Restricted) é que o experimentador não deve usar o nome da pessoa para inferir a equivalência ou não de dois rostos em duas imagens diferentes, que não são explicitamente fornecidos no conjunto de treinamento.
Sob o paradigma de treinamento restrito à imagem, o pesquisador deve descartar os nomes reais associados a um par de imagens de treinamento e ficar apenas com as informações sobre se um par de imagens é matched ou mismatched.
Assim, se os pares (10,12) e (42,50) de George_W_Bush são dados explicitamente em um conjunto de treinamento, então, sob o paradigma de treinamento restrito à imagem, não há como de maneira simples, inferir que a imagem 10 e a imagem 42 de George_W_Bush eram a mesma pessoa e, portanto, esse par de imagem não deve ser adicionado ao conjunto de treinamento.
Observe que, sob esse paradigma, ainda é possível aumentar os dados de treinamento comparando a similaridade da imagem, em oposição a equivalência de nomes.
Por exemplo, se a 1ª e a 2ª imagens de uma pessoa formam um par de treinamento matched, e a 2ª e 3ª imagens da mesma pessoa formam outro par matched para treinamento, pode-se inferir a partir da equivalência de imagens que a 1ª e 3ª imagens são da mesma pessoa e adicionar esse par ao conjunto de treinamento como um par correspondente(matched).
Esse tipo de procedimento funciona sob paradigma restrito à imagem(Image-Restricted).
Ambas as views do banco de dados suportam o paradigma de treinamento restrito à imagem(Image-Restricted) .
Na view1 do banco de dados, o arquivo pairsDevTrain.txt destina-se a dá suporte ao Image-Restricted e pairsDevTest.txt contém os pares de teste.
Na view2, o arquivo pairs.txt dá suporte ao Image-Restricted.
Treinamento com Image-Unrestricted
A ideia por trás do paradigma de treinamento irrestrito a imagens é que pode-se formar tantos pares matched e mismatched quanto se queira, a partir de um conjunto de imagens rotuladas com nomes.
Para suportar esse uso do banco de dados, os criadores do LFW definiram subconjuntos de pessoas, em vez de pares de imagens, que podem ser usadas como base para formar pares arbitrários de imagens correspondentes(matched) e incompatíveis(mismatched).
View1
Na view1 do banco de dados, os arquivos peopleDevTrain.txt e peopleDevTest.txt podem ser usados para criar pares arbitrários de imagens de treinamento e teste.
Por exemplo, para criar pares de treinamento mismatched, escolha duas pessoas em peopleDevTrain.txt, escolha uma imagem de cada pessoa e adicione o par ao conjunto de dados.
Os pares não devem ser construídos usando misturas de imagens de conjuntos de treinamento e teste (Image-Unrestricted).
View2
Na view2, o arquivo people.txt dá suporte ao paradigma de treinamento irrestrito à imagens.
Os pares de treinamento devem ser formados apenas usando pares de imagens dos mesmos subconjuntos.
Portanto, para formar um par de imagens incompatíveis, escolha duas pessoas do mesmo subconjunto, escolha uma imagem de cada pessoa e adicione o par ao conjunto de treinamento.
Nota. Na view2 do banco de dados, destinado apenas a relatórios de desempenho, os dados do teste são totalmente especificados pelo pairs.txt e não deve ser construído usando o paradigma irrestrito.
O paradigma irrestrito é apenas para usar na criação de dados de treinamento.
Devido à complexidade adicional do uso do paradigma de treinamento irrestrito de imagens, eles sugerem que os usuários comecem com o paradigma restrito à imagem usando os pares descritos em pairsDevTrain.txt, pairsDevTest.txt, e para relatórios de desempenho, pairs.txt.
Obs. Mais tarde, se os experimentadores acreditarem que seu algoritmo pode se beneficiar significativamente de quantidades maiores de dados de treinamento, eles podem desejar considerar o uso do paradigma irrestrito à imagens.
Em ambos os casos, deve ficar claro em todas as publicações qual paradigma de treinamento foi usado para treinar os classificadores para um determinado resultado de teste.
Fluxo(Pipeline) de detecção, alinhamento e reconhecimento
Muitos aplicativos do mundo real desejam automaticamente detectar, alinhar e reconhecer rostos em uma imagem estática ou em um vídeo de uma cena maior.
Assim, o reconhecimento facial é frequentemente descrito naturalmente como parte de um DAR (Detection-Alignment-Recognition).

Detecção, alinhamento e reconhecimento
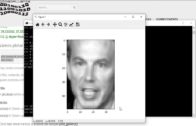
Toda imagem de rosto no LFW é a saída do algoritmo de detecção de face Viola-Jones.
A motivação para isso é a seguinte.
Se alguém pode desenvolver um algoritmo de alinhamento de rosto e subsequentemente um algoritmo de reconhecimento que funcione diretamente no LFW, é provável que também funcione bem em um sistema ponta a ponta que usa o detector Viola-Jones como um primeiro passo.
Dessa forma, permite que o pesquisador se concentre nos problemas de alinhamento e reconhecimento ao invés do problema de detecção.
Resumo dos detalhes da construção do LFW
- Coleta de imagens brutas(raw)
- Execução de um detector de rosto e eliminação manual de falsos positivos
- Eliminação de duplicatas de fotos
- Por os rótulos (nomear) das pessoas detectadas
- Cortar e redimensionar as faces detectadas
- Formar pares do conjunto de treinamento e teste para a view1 e view2 do banco de dados