HDFS,YARN e os tipos de nós
Link da documentação oficial do Hadoop:
http://hadoop.apache.org/
Link para o download do putty:
https://www.putty.org/
Link para o download do WINSCP:
https://winscp.net/eng/download.php
Link do meu Github:
https://github.com/toticavalcanti

COMPONENTES PRINCIPAIS DO HADOOP
O HADOOP POSSUI DOIS COMPONENTES PRINCIPAIS QUE IMPLEMENTAM O ARMAZENAMENTO E O PROCESSAMENTO DISTRIBUÍDO:
- O HDFS QUE GERENCIA OS DADOS ARMAZENADOS EM DISCOS NO CLUSTER
- E O YARN QUE GERENCIA OS RECURSOS DO CLUSTER, ALOCANDO RECURSOS COMPUTACIONAIS PARA APLICAÇÕES QUE QUEIRAM FAZER UM PROCESSAMENTO DISTRIBUÍDO
- TODO O MAPREDUCE ORIGINAL ESTÁ IMPLEMENTADO AGORA NO YARN, ASSIM COMO O APACHE GIRAPH (PROCESSAMENTO EM GRAFOS)E O APACHE SPARK (PROCESSAMENTO EM MEMÓRIA).
O HDFS E O YARN TRABALHAM EM CONJUNTO PARA MINIMIZAR O VOLUME DE TRÁFEGO DE REDE NO CLUSTER.
A PRINCIPAL PREOCUPAÇÃO É GARANTIR QUE OS DADOS SEJAM LOCAIS AO PROCESSAMENTO SOLICIDADO.
O HDFS E O YARN FORMAM UMA PLATAFORMA SOBRE A QUAL APLICAÇÕES BIG DATA SÃO CONSTRUÍDAS.
FORMAM UM SISTEMA OPERACIONAL PARA BIG DATA.
CONSISTE EM VÁRIOS PROCESSOS DAEMON, RODANDO EM SEGUNDO PLANO.
DOIS TIPOS DE NÓS BÁSICOS
NÓS MESTRES (MASTERS) – COORDENA OS NÓS TRABALHADORES, GERALMENTE SÃO OS PONTOS DE ENTRADA PARA O ACESSO DO USUÁRIO AO CLUSTER.
NÓS TRABALHADORES – ACEITAM AS TAREFAS DESIGNADAS PELOS NÓS MESTRES, PARA ARMAZENAR OU LER DADOS OU EXECUTAR UMA APLICAÇÃO EM PARTICULAR.
TANTO O HDFS COMO O YARN TÊM VÁRIOS SERVIÇOS MESTRES RESPONSÁVEIS PELA COORDENAÇÃO DOS SERVIÇOS TRABALHADORES QUE EXECUTAM EM CADA NÓ.
SERVIÇOS DO HDFS
NameNode (MESTRE) – ARMAZENA A ÁRVORE DE DIRETÓRIOS DO SISTEMA DE ARQUIVOS, METADADOS DE ARQUIVOS E AS LOCALIZAÇÕES DE CADA ARQUIVO NO CLUSTER.
ELE NÃO ARMAZENA DADOS E NEM PASSA DO DATANODE AO CLIENTE, O QUE ELE FAZ É APONTAR OS DATANODES CORRETOS AOS CLIENTES.
NameNode SECUNDÁRIO (MESTRE) – EXECUTAM TAREFAS DE MANUTENÇÃO (HOUSEKEEPING) E DE PONTOS DE VERIFICAÇÃO (CHECKPOINTING) EM NOME DO NAMENODE (ELE NÃO É UM NAMENODE DE BACKUP!)
DataNode (TRABALHADOR) – ARMAZENA E ADMINISTRA BLOCOS HDFS NO DISCO LOCAL E INFORMA A SAÚDE E O STATUS DE REPOSITÓRIOS INDIVIDUAIS DE DADOS AO NameNode.
SERVIÇOS DO YARN
ResourceManager (MESTRE) – ALOCA E MONITORA RECURSOS DISPONÍVEIS NO CLUSTER (MEMÓRIA E PROCESSADORES) PARA AS APLICAÇÕES E TRATA DO ESCALONAMENTO DOS JOBS NO CLUSTER.
ApplicationMaster (MESTRE) – COORDENA UMA APLICAÇÃO EM PARTICULAR EXECUTADA NO CLUSTER DE ACORDO COM O ESCALONAMENTO FEITO PELO ResourceManager.
NodeManager (TRABALHADOR) – EXECUTA E ADMINISTRA TAREFAS DE PROCESSAMENTO EM UM NÓ INDIVIDUAL E INFORMA SOBRE A SAÚDE E O STATUS DAS TAREFAS À MEDIDA QUE ELAS EXECUTAM.
HADOOP NA PRÁTICA
LINK PARA BAIXAR shakespeare.txt https://github.com/toticavalcanti/Curso_Hadoop/raw/master/shakespeare.txt
PRÉ-REQUISITO:
- TER O VIRTUAL BOX, TER A MÁQUINA CLOUDERA JÁ IMPORTADA E CONFIGURADA COMO MOSTRADO NA AULA PASSADA.
- TER O PUTTY E O WINSCP JÁ INSTALADOS NA SUA MÁQUINA FÍSICA, NO MEU CASO WINDOWS 10. SÃO SOFTWARES GRATUÍTOS.
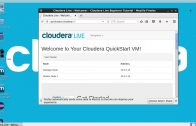
CUMPRIDO OS REQUISITOS, VAMOS INICIAR A MÁQUINA CLOUDERA.
DEPOIS DE INICIADA, VAMOS USAR O WINSCP PARA TRANFERIR O ARQUIVO shakespeare.txt PARA O SISTEMA DE ARQUIVOS LOCAL DA MÁQUINA CLOUDERA.
Obrigado
Até a próxima