Aula 29 – Tensor Flow – Keras – Conjunto de dados CIFAR-10 – VGG 3 – Data Augmentation
Aula 29 – Tensor Flow – Keras – Conjunto de dados CIFAR-10 – VGG 3 – Data Augmentation
Voltar para página principal do blog
Todas as aulas desse curso
Aula 28 Aula 30 (Ainda não disponível)
Meu github:
https://github.com/toticavalcanti
Documentação oficial do TensorFlow:
https://www.tensorflow.org/
Quer aprender python3 de graça e com certificado? Acesse então:
https://workover.com.br/python-codigo-fluente

Python com Tensorflow
Se gostarem do conteúdo dêem um joinha 👍 na página do Código Fluente no
Facebook
https://digitalinnovation.one/
Aproveito para deixar meus link de afiliados:
Hostinger
Digital Ocean
One.com
Toti:
https://www.youtube.com/channel/UCUEtjLuDpcOvR3mIUr-viOA
Backing track / Play-along:
https://www.youtube.com/channel/UCT3TryVMqTqYBjf5g5WAHfA
Código Fluente
https://www.youtube.com/channel/UCgn-O-88XBAwdG9gUWkkb0w
Putz!
https://www.youtube.com/channel/UCZXop2-CECwyFYmHbhnAkAw
Fiquem a vontade para me adicionar ao linkedin.
Notebook da aula
PIX para doações

PIX Nubank
Se quiser copiar o código do PIX:
00020126580014BR.GOV.BCB.PIX013643c5f950-535b-4658-b91f-1f1d135fe4105204000053039865802BR5925Antonio Cavalcante de Pau6009SAO PAULO61080540900062070503***6304946B
Aula 29 – Tensor Flow – Keras – Conjunto de dados CIFAR-10 – VGG 3 – Data Augmentation
CIFAR-10
Recapitulando o que já fizemos
Partimos de um modelo base, um base line, que é a arquitetura VGG3.
Depois aplicamos as técnicas de regularização: Dropout na aula 27 e Weight Decay na aula 28.
Resultados:
VGG3 + Weight Decay – 74,84%
VGG3 + Dropout – 82,33%
Nessa aula iremos usar a técnica: Data Augmentation.
Melhorando o Modelo
No aumento de dados (Data Augmentation), fazemos cópias dos exemplos do conjunto de dados de treinamento com pequenas modificações aleatórias.
A técnica tem um efeito de regularização, pois expande o conjunto de dados de treinamento e permite que o modelo aprenda os mesmos recursos gerais, embora de uma maneira mais generalizada.
Existem muitos tipos de aumento de dados que podem ser aplicados.
Já que o conjunto de dados é composto de pequenas fotos de objetos, não queremos usar um aumento que distorça muito as imagens, para que recursos úteis nelas, possam ser preservados e usados.
Os tipos de aumentos aleatórios que podem ser úteis incluem: inversão horizontal, pequenos deslocamentos da imagem e talvez, um pequeno zoom ou corte da imagem.
Investigaremos o efeito de um aumento simples na imagem, especificamente viradas horizontais e mudanças de 20% na altura e largura, usaremos o shear_range, que especifica o ângulo para a inclinação da imagem em graus.

shear_range
Vamos usar a classe ImageDataGenerator do Keras para isso.
# construct the training image generator for data augmentation
aug = ImageDataGenerator(
rotation_range = 20,
zoom_range = 0.15,
width_shift_range = 0.2,
height_shift_range = 0.2,
shear_range = 0.15,
horizontal_flip = True,
fill_mode = "nearest"
)Definiremos o batch_size como 32 e o número de épocas 100.
Lembrando que batch_size é o número de amostras que serão propagadas pela rede.
# initialize the number of epochs and batch size
EPOCHS = 100
BS = 32
Usaremos o aug, EPOCHS e BS no treinamento, isto é, no model.fit().
Vamos passar o aug para a função model.fit(), chamando o método flow().
O método flow() que cria um iterador.
Podemos facilmente iterar e gerar os lotes de dados através dele.
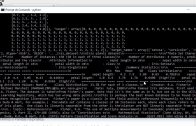
model.fit(
aug.flow(
trainX, trainY, batch_size = BS
),
validation_data = (testX, testY),
steps_per_epoch = len(trainX) // BS,
epochs = EPOCHS
)
Reforçando, o que fizemos até agora foi, na aula 27, mudamos o modelo da aula 26, que é o base line, ou seja, o VGG3, inserindo dropout, na aula 28, modificamos novamente o modelo da aula 26, dessa vez para inserir o weight decay.
Dessa vez, para o aumento de dados, não modificaremos em nada o modelo base, criado na aula 11, isto é, não vamos mexer na função define_model().
Anaconda
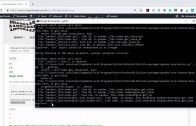
O código dessa aula, eu rodei o código usando meu processamento local, já que o colab impõe limites de processamento e tempo em seu plano free.
Para isso, usei o jupyter notebook do Anaconda, criei um ambiente chamado tensorflow, instalei tudo que precisamos nele: o jupyter, o CMD.exe, o matplotlib, o tensorflow, o tensorboard…
Antes de executar o notebook localmente
Antes de rodar o notebook localmente, no painel do anaconda:
Painel do Anaconda
Abra o prompt no ambiente que você criou, no meu caso, o ambiente tensorflow, e rode na pasta do notebook o seguinte comando:
tensorboard --logdir logs --port 6006
O comando acima cria a pasta logs na pasta do notebook, e é onde serão colocados os dados gerados durante o treinamento da rede, dados relativos a como a rede evoluiu durante o treinamento, baseado nas precisões nos dados de treino e validação.
É onde o tensorboard vai ler os dados para plotar os gráficos, e também definimos a porta como 6006.
OBS. Na aula https://www.codigofluente.com.br/aula-03-computacao-quantica-instalando-o-anaconda-e-o-qiskit/ de computação quântica, eu mostro como instalar o Anaconda.
Conclusões
Lembre-se que os resultados podem variar devido à natureza estocástica do algoritmo ou procedimento de avaliação, ou por diferenças na precisão numérica.
Considere executar o exemplo algumas vezes e compare o resultado médio.
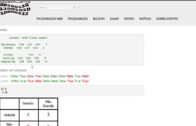
Neste caso, vemos outra grande melhoria no desempenho do modelo, muito parecido com o que vimos com o abandono, ou, em inglês, Dropout.
A precisão foi de: 84,77%.
Os gráficos mostram que o modelo continuou aprendendo até as 100 épocas, por isso, talvez valha a pena rodar o modelo com mais épocas e testar até onde ele segue aprendendo.
Os resultados sugerem que talvez uma configuração de modelo que use Dropout e Data Augmentation pode ser eficaz.
É exatamente isso que iremos fazer no próximo experimento, misturar as duas técnicas.
Por essa aula é só, na próxima, vamos explorar a técnica de regularização conhecida como Aumento de dados (Data Augmentation).
Voltar para página principal do blog
Todas as aulas desse curso
Aula 28 Aula 30 (Ainda não disponível)
Meu github:
https://github.com/toticavalcanti
Se gostarem do conteúdo dêem um joinha 👍 na página do Código Fluente no
Facebook
Link do código fluente no Pinterest
Novamente deixo meus link de afiliados:
Hostinger
Digital Ocean
One.com
Obrigado, até a próxima e bons estudos. 😉