Aula 24 – Tensor Flow – Keras – Conjunto de dados CIFAR-10
Aula 24 – Tensor Flow – Keras – Conjunto de dados CIFAR-10
Voltar para página principal do blog
Todas as aulas desse curso
Aula 23 Aula 25 (Ainda não disponível)
Meu github:
https://github.com/toticavalcanti
Documentação oficial do TensorFlow:
https://www.tensorflow.org/
Quer aprender python3 de graça e com certificado? Acesse então:
https://workover.com.br/python-codigo-fluente

Python com Tensorflow
Se gostarem do conteúdo dêem um joinha 👍 na página do Código Fluente no
Facebook
https://digitalinnovation.one/
Aproveito para deixar meus link de afiliados:
Hostinger
Digital Ocean
One.com
Toti:
https://www.youtube.com/channel/UCUEtjLuDpcOvR3mIUr-viOA
Backing track / Play-along:
https://www.youtube.com/channel/UCT3TryVMqTqYBjf5g5WAHfA
Código Fluente
https://www.youtube.com/channel/UCgn-O-88XBAwdG9gUWkkb0w
Putz!
https://www.youtube.com/channel/UCZXop2-CECwyFYmHbhnAkAw
Fiquem a vontade para me adicionar ao linkedin.
Notebook da aula
Aula 24 – Tensor Flow – Keras – Conjunto de dados CIFAR-10
CIFAR-10
CIFAR é um acrônimo que significa Canadian Institute For Advanced Research (Instituto Canadense de Pesquisa Avançada) e o conjunto de dados CIFAR-10 foi desenvolvido junto com o conjunto de dados CIFAR-100 por pesquisadores do instituto CIFAR.
O conjunto de dados é composto por 60.000 fotografias coloridas de 32 × 32 pixels de objetos de 10 classes, como sapos, pássaros, gatos, navios, etc.
Os rótulos da classe e seus valores inteiros associados padrão estão listados abaixo.
- 0: airplane (avião)
- 1: automobile (automóvel)
- 2: bird (pássaro)
- 3: cat (gato)
- 4: deer (veado)
- 5: dog (cachorro)
- 6: frog (sapo)
- 7: horse (cavalo)
- 8: ship (navio)
- 9: truck (caminhão)
Essas são imagens muito pequenas, muito menores do que uma fotografia típica, e o conjunto de dados foi planejado para pesquisa de visão computacional.
O CIFAR-10 é um conjunto de dados bem conhecido e amplamente utilizado para referência na medição de algoritmos de visão computacional no campo de aprendizado de máquina.
O problema está resolvido.
É relativamente simples alcançar uma precisão de classificação de 80%.
O melhor desempenho no problema é alcançado por redes neurais convolucionais com uma precisão de classificação pouco acima de 90% no conjunto de dados de teste.
VGG (Visual Geometry Group)
Usaremos o VGG (Visual Geometry Group), que é uma arquitetura padrão de Rede Neural Convolucional (CNN) profunda com várias camadas.
O “profundo” se refere ao número de camadas com VGG-16 ou VGG-19 consistindo em 16 e 19 camadas convolucionais.
A arquitetura VGG é a base inovadora dos modelos de reconhecimento de objetos.
Desenvolvido como uma rede neural profunda, o VGG também supera as linhas base em muitas tarefas e conjuntos de dados além do ImageNet.
Além disso, é uma das arquiteturas de reconhecimento de imagem mais populares.
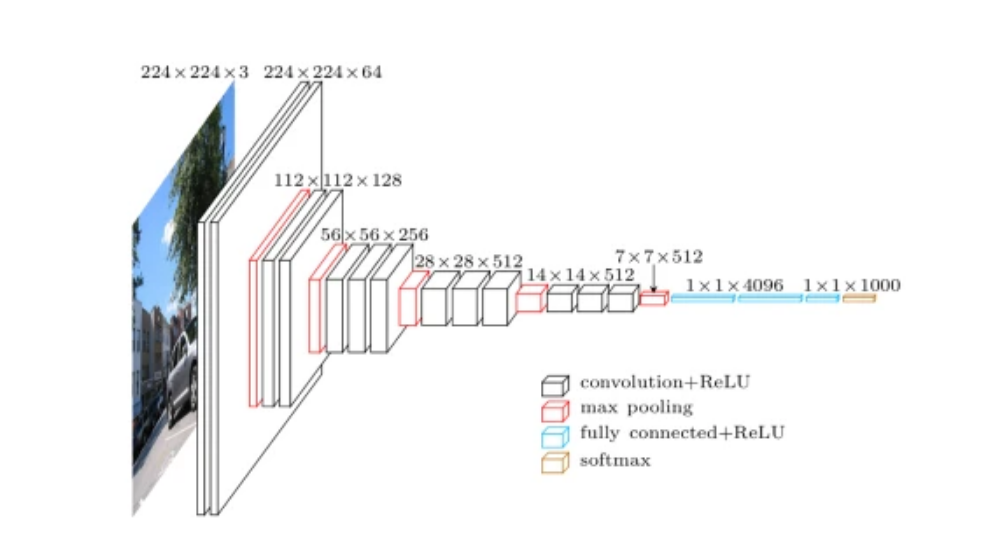
VGG (Grupo de Geometria Visual)
Nesse primeiro exemplo vamos usar a arquitetura VGG 1, depois vamos deixar nossa rede mais profunda, com mais camadas e vamos testar com VGG 2 e também com o VGG 3.
Por último, no exemplo final, com maior precisão, vamos usar BatchNormalization().
A normalização em lotes (BatchNormalization) é uma técnica para treinar redes neurais muito profundas que padroniza as entradas de uma camada para cada mini lote.
Isso tem o efeito de estabilizar o processo de aprendizagem e reduzir drasticamente o número de períodos de treinamento necessários para treinar redes profundas, acelerando esse processo.
Para compensar essa aceleração, podemos aumentar a regularização alterando o dropout de um padrão fixo para um padrão crescente.