Introdução ao Map-Reduce
Link da documentação oficial:
http://hadoop.apache.org/
Github:
https://github.com/toticavalcanti

Hadoop Map Reduce
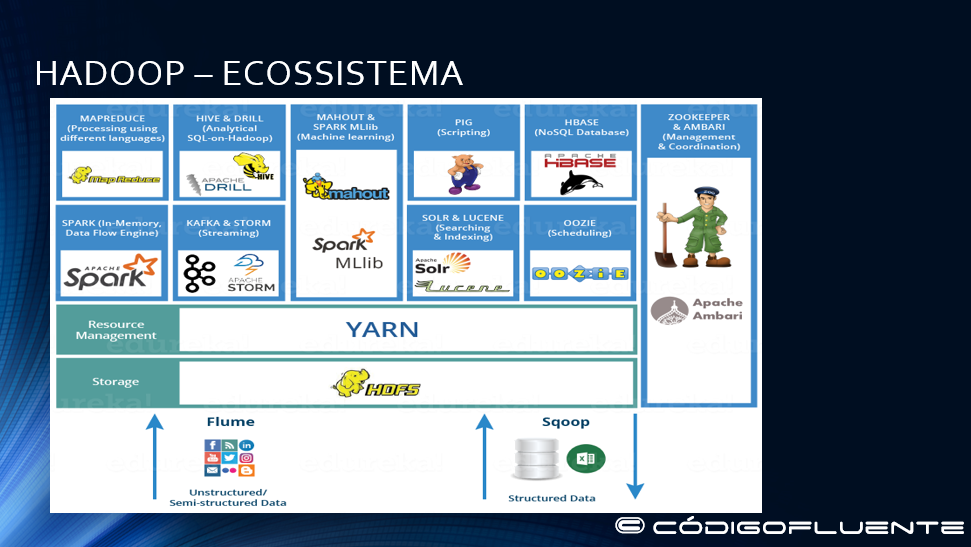
Visão geral do ecossistema Hadoop
- O MAPREDUCE DIVIDE VOLUMES IMENSOS DE DADOS EM PARTES PEQUENAS, QUE SÃO ENTÃO ESPALHADAS POR MUITOS COMPUTADORES
- EM VEZ DE MOVER DADOS PARA UM SOFTWARE DE PROCESSAMENTO – O QUE SERIA LENTO COM VOLUMES GRANDES DE DADOS – O PROCESSAMENTO É MOVIDO PARA ONDE ESTÃO OS DADOS, O QUE TRAZ MAIS VELOCIDADE.
- É POSSÍVEL RODAR O MAPREDUCE EM MÁQUINAS RELATIVAMENTE MODESTAS QUANDO COMPARADAS COM O EQUIPAMENTO DE PONTA DE UM DATA CENTER TRADICIONAL
VISÃO GERAL DO MAP-REDUCE
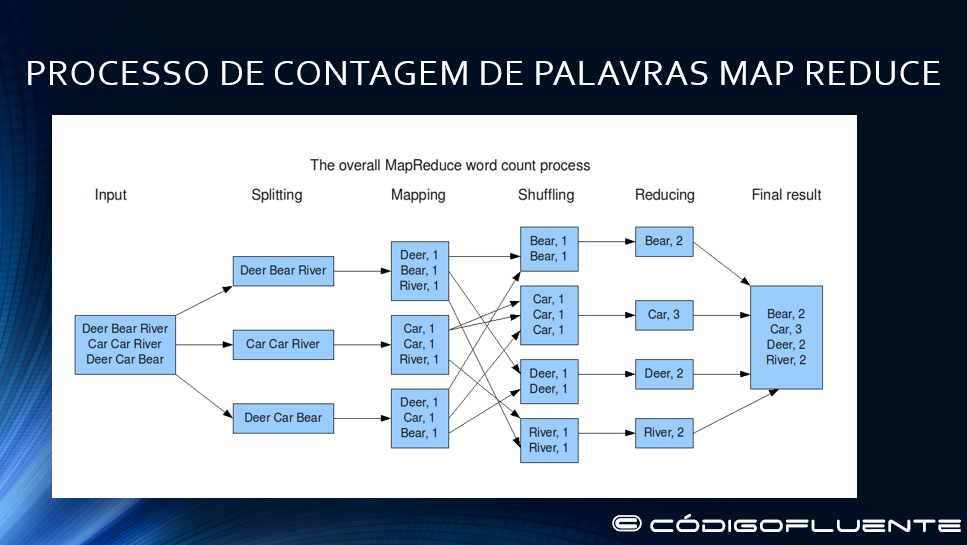
Visão geral do map-reduce




Visão geral do map-reduce



- O INPUT SÃO CARTAS DE BARALHO
- O OBJETIVO E SOMAR OS VALORES DAS CARTAS DE CADA NAIPE DISTINTO DO BARALHO
- CARTAS NUMÉRICAS SÃO CONSIDERADOS DADOS VÁLIDOS, CARTAS DE FIGURAS COMO VALETES, DAMAS, REIS E CORINGAS SÃO CONSIDERADOS DADOS INVÁLIDOS (BAD DATA)
FASE SPLITTING E MAPPING






















FASE SPLITTING (DIVIDINDO OS DADOS)

- DOIS NÓS DE PROCESSAMENTO TRABALHANDO JUNTOS
- CADA QUADRADO BRANCO É UM NÓ (MÁQUINA) DO CLUSTER HADOOP





- COMO VIMOS NA AULA ANTERIOR OS ARQUIVOS SÃO DIVIDIDOS EM BLOCOS
- QUANDO UM MAPPER ESTÁ OPERANDO EM UM ARQUIVO DE UM TERABYTE, POR EXEMPLO, ELE ESTÁ OPERANDO EM UM BLOCO E NÃO NO ARQUIVO INTEIRO
- CADA NÓ DO CLUSTER OPERA EM UM PEDAÇO DO ARQUIVO
- VÁRIOS NÓS PODEM OPERAR EM DIFERENTES BLOCOS DO MESMO ARQUIVO AO MESMO TEMPO
- QUANDO TERMINA O PROCESSAMENTO, O ARQUIVO É COMBINADO BASEADO NA CHAVE, OS REDUCERS EXECUTAM SOBRE CHAVES DIFERENTES
- O BENEFÍCIL É QUE O PROBLEMA É PROCESSADO POR VÁRIOS NÓS AO MESMO TEMPO AO INVÉS DE SER PROCESSADO EM UM ÚNICO NÓ, OU SEJA, EM UMA ÚNICA MÁQUINA